Research
From the picoliter to the pilot scale for designing, evolving and applying novel molecules and catalysts for fine chemistry and pharma
Our Research Interests:
Metrazymes Project

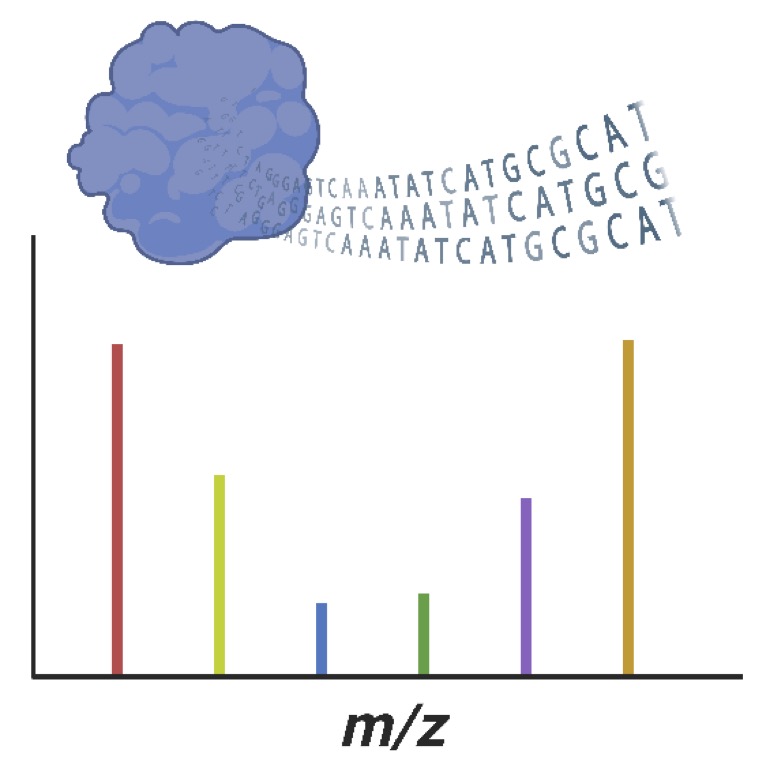
A versatile enzyme screening technology must be broadly applicable for various reaction types and it must be high-throughput.
Mass spectrometry (MS) fulfills the first criterium, but throughput in line with today’s standards has not yet been achieved. The challenge lies in adapting MS to miniaturized sample handling formats which, while high-throughput, prevent the identification of enzyme variants.
We aim to overcome this limitation by linking enzyme activity to the corresponding genetic information in a single measurement.
GreenerRPP Project


High-throughput screening methods are essential to accelerate enzyme discovery and engineering, but many existing approaches are limited by cumbersome individual assay development. We are addressing these challenges by developing a platform that integrates droplet-based microfluidics with mass spectrometry for rapid and label-free enzyme screening. We design and optimize microfluidic setups tailored for droplet-based enzyme assays and develop custom interfaces to efficiently couple microfluidic devices with MS systems.



MassDrop is integrating label-free analytical methods into the directed evolution of enzymes used for antibody-drug conjugation to drastically expand the use of microfluidic screening methods beyond the realm of fluorescent model systems into the realm of pharmaceutically relevant reactions. The Bioprocess Group, in collaboration with CSEM, is advancing innovative technologies such as novel genotype-phenotype linkage of enzyme libraries, cell autolysis and advanced microfluidic devices coupled to mass spectrometry, in order to establish the MassDrop screening technology.
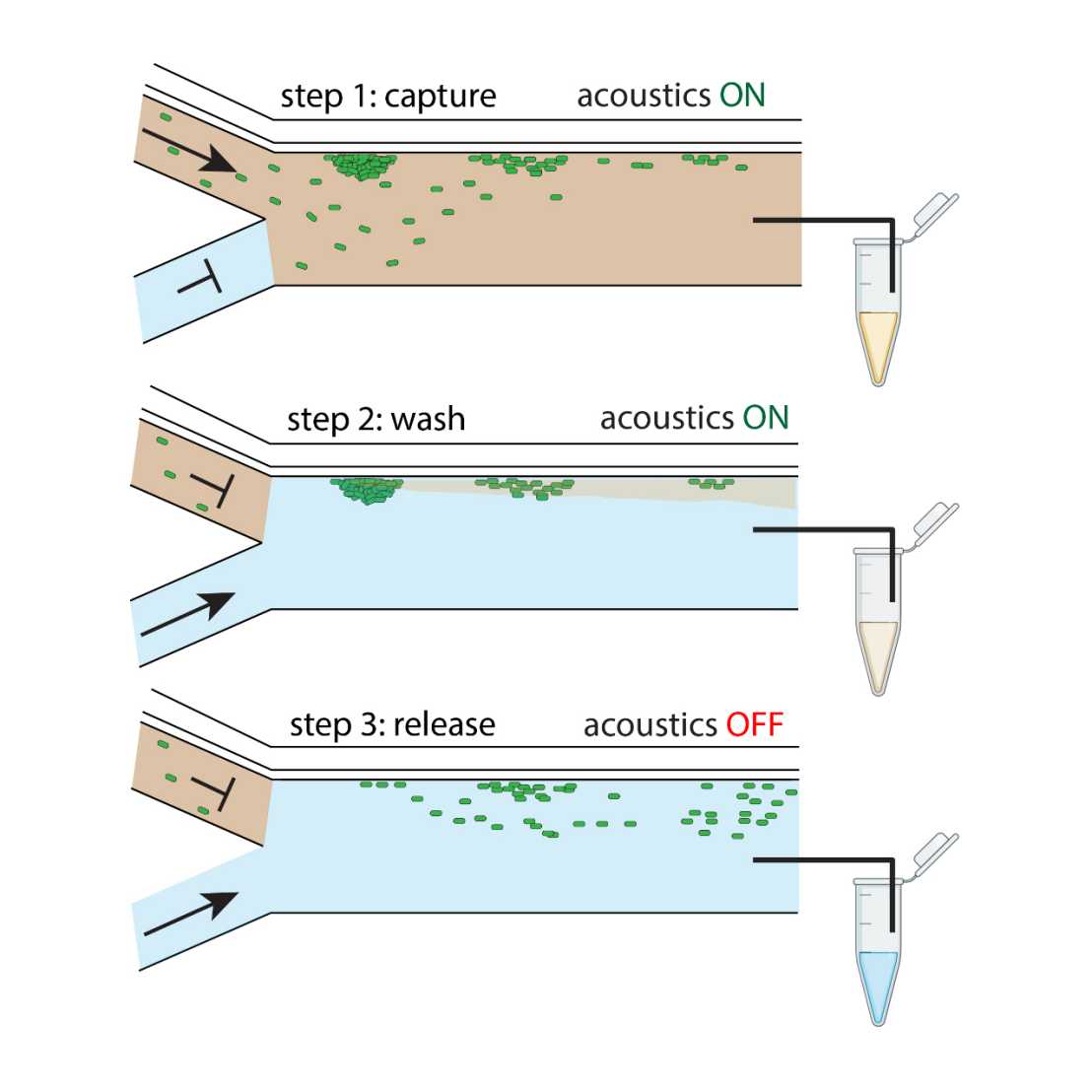
We created a small device that uses sound waves to gently trap E. coli bacteria allowing for medium exchange and thus efficient transformation. With an improved etching process, we could add a thin wall between two tiny channels that helps create fluid movement to trap the bacteria more effectively. This low-volume method replaces bulky centrifuges and paves the way for miniaturizing a plethora of microbiological and molecular engineering protocols, such as automated genome editing.
DNA recorders for comprehensive screening of enzyme libraries
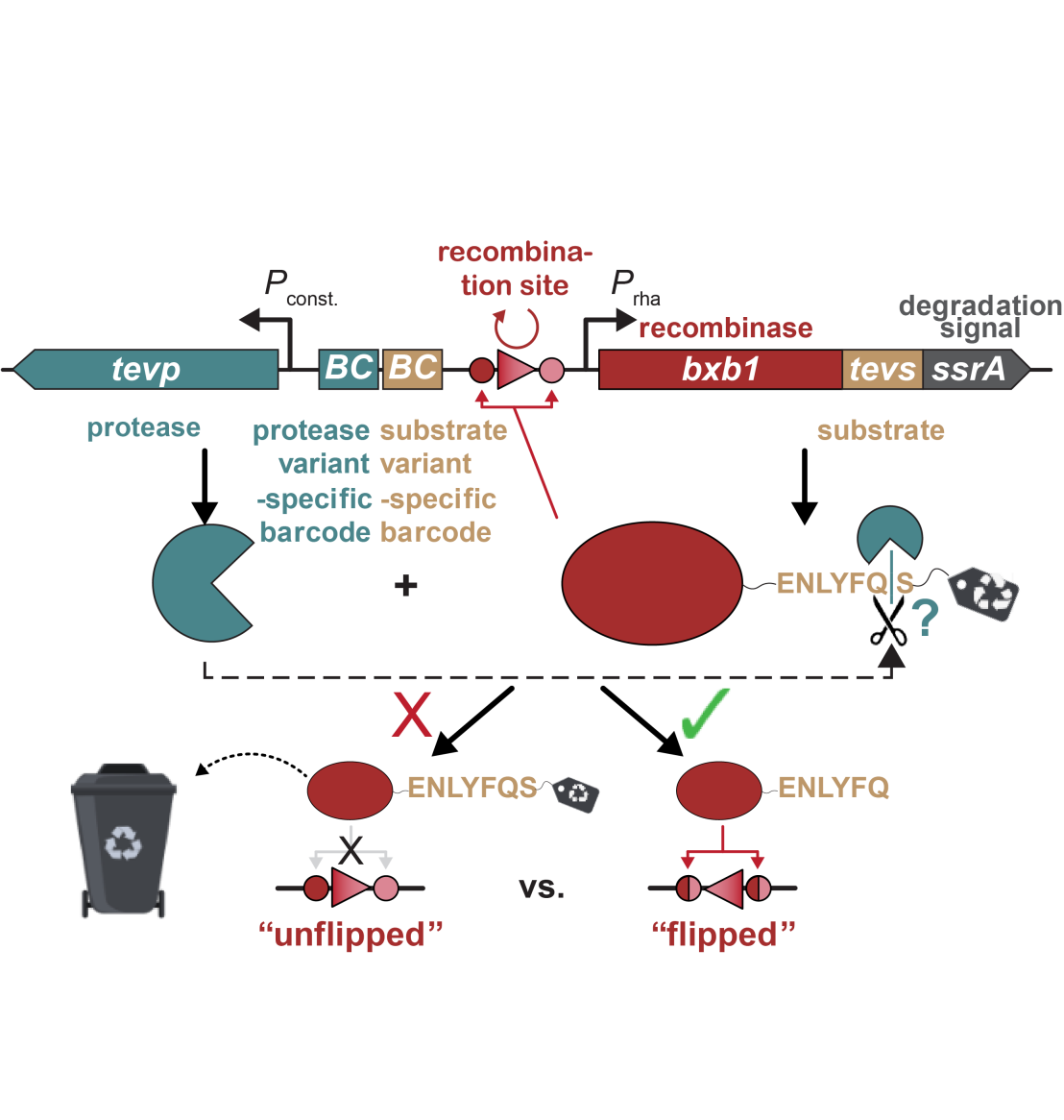
The advent of next-generation sequencing has fundamentally changed the analytical landscape of high-throughput screening. Rather than cherry-picking a few variants from a large library, the target has become to evaluate the entire library (typically involving NGS) to discern trends and train machine learning models. So one of the new challenges is to link the function that is to be evolved to DNA sequence. We built the uAspire platform to link the (level of) function of biomolecules to DNA sequence changes and adapted it to record the activity of enzymes, specifically proteases in what might be the smallest ever available reactor, the bacterial cell.
external page DOI:10.1038/s41467-020-17222-4
In Print: Data-driven protease engineering by DNA-recording and epistasis aware machine learning DOI: 10.1038/s41467-025-60622-7
nL Reactors
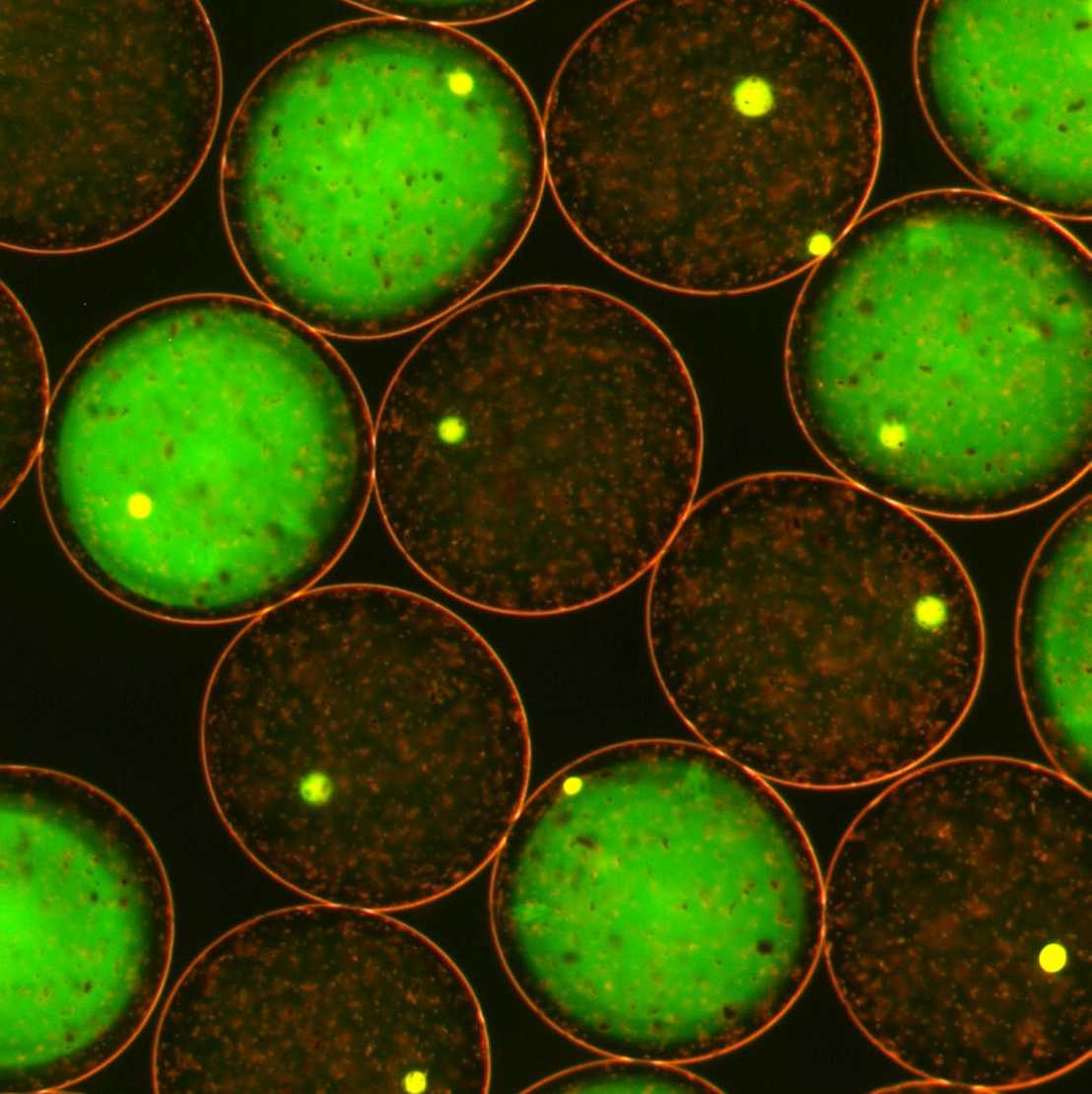
Modern screening platforms recapitulate complex operations in miniaturized formats and interface the outcome with a screenable signal. With the nanoliter (nL) format, we built a platform around the use of alginate droplets that can harbor and expand any cell type from bacterial to mammalian, allows growing millions of separate cultures in mL-volumes separately or under one set of environmental conditions, and can be evaluated by fluorescence or density. We used this platform primarily to screen strains with improved production performance for vitamins or proteins. The technology is the basis for two of our early spin-offs, external page FGen and external page Memo Therapeutics (Memo has currently its first antibody, Potravitug, in clinical phase II trials). We also used it for the development of novel peptide antibiotics (nanoFleming).
external page DOI:10.1038/nchem.2301
external page DOI:10.1038/s41598-018-20877-1
Operons

Operons, a type of genetic construct, in which multiple open reading frames are transcribed from a single promoter, is commonly employed in synthetic biology. Design principles that go into the construction of synthetic operons is limited, and synthetic biologists have to rely on ad hoc rules to provide an initial design. This initial design then has to go through multiple design-build-test cycles and the screening of libraries before the protein expression is fine-tuned to meet the performance requirements of the system. A better understanding of the most important elements influencing the expression levels of a particular operon allowing for reliable expression level predictions could speed up this optimization process to construct new systems.
To acheive this, we take a new approach, using arrangements of up to seven fluorescent proteins coupled with by employing high-throughput experimenting and machine learning.
RedLibs

RedLibs is an algorithm that allows for the rational design of smart combinatorial libraries for pathway optimization thereby minimizing the use of experimental resources. We apply these smart libraries to ribosome binding sites to vary enzyme expression levels in a combinatorial fashion. This allows us to reduce the experimental effort of screening for the optimized variants to just a couple of microtiter plates


We aim for large-scale, in vivo production of mRNAs for purposes such as vaccination or gene therapy.
To this end, we explore “cloaked and decloaking" of mRNAs. Cloaked or protected forms of mRNAs could increase their bioproduction yield in E. coli by preventing degradation; however uncloaking is critical post-isolation. In parallel, this project focuses on producing synthetic mRNA circles. We are developing a split-reporter-based approach to link synthetic mRNA engineering with bacterial growth.



We investigate how one of life's most essential molecular machines – the polymerases that replicate DNA and RNA – could have emerged from simpler predecessors billions of years ago. Using protein engineering and high throughput screening, we aim to systematically screen primordial protein motifs to identify proteinaceous "proto-polymerases" that might have existed in prebiotic conditions. This experimental approach to early evolution provides insights into the molecular requirements for the origin of heredity and the probability of peptide-catalysed replication in primordial environments. This work bridges structural biology, evolutionary biochemistry, and origin-of-life research to address fundamental questions about how complex biological systems first arose.
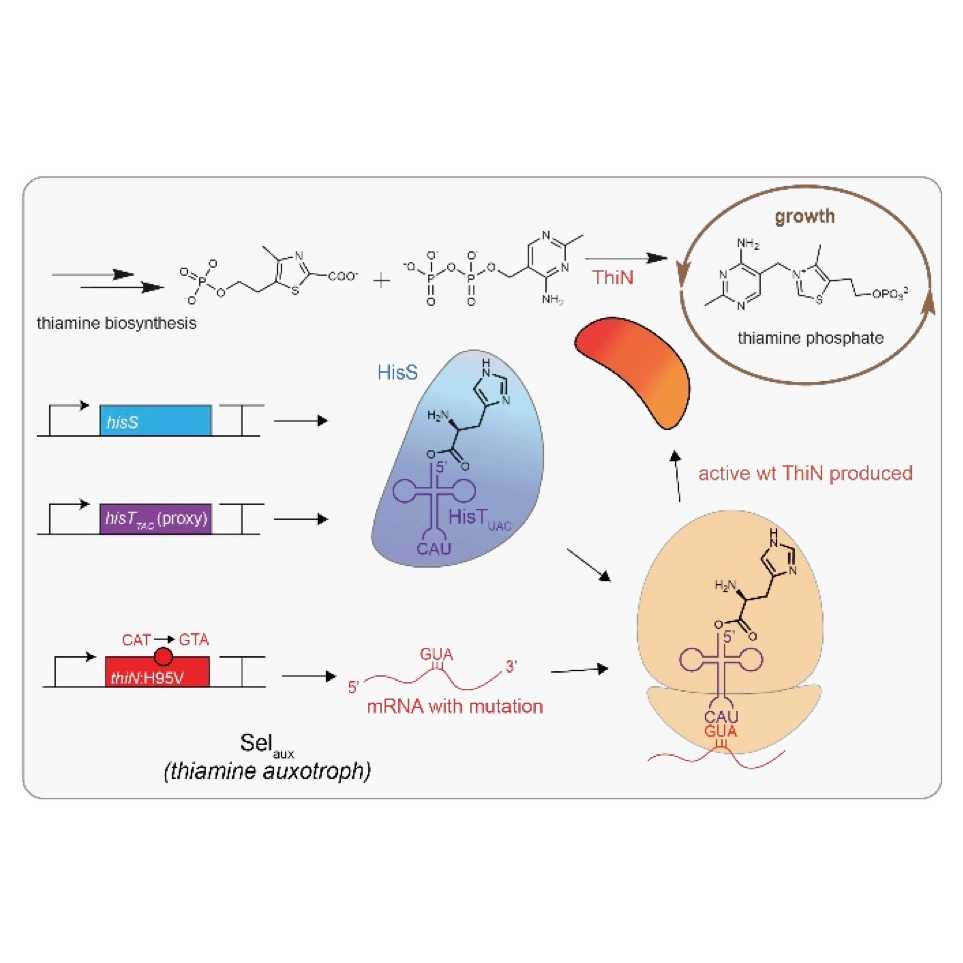
We developed an ultrasensitive and highly reliable vitamin-based suppression system in E. coli that can be exploited for the evolutionary adaptation towards in vivo activity of non-canonical decoders of the genetic code.The system was successfully applied to evolve an E. coli strain to use a non-cloverleaf-folded tRNA in translation for the first time.
external page https://doi.org/10.1093/nar/gkae806
tRNA Deletions
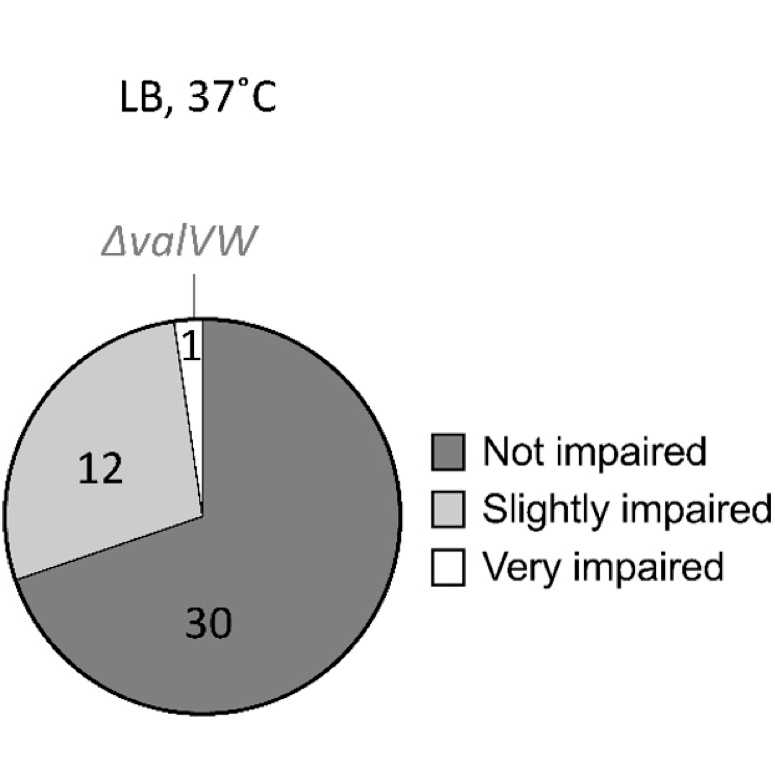
We constructed tRNA deletion strains to systematically investigate the essentiality of all E. coli tRNAs, the phenotypic effects by their removal, and the resulting cellular response to it.
external page https://www.nature.com/articles/s41598-024-73407-7
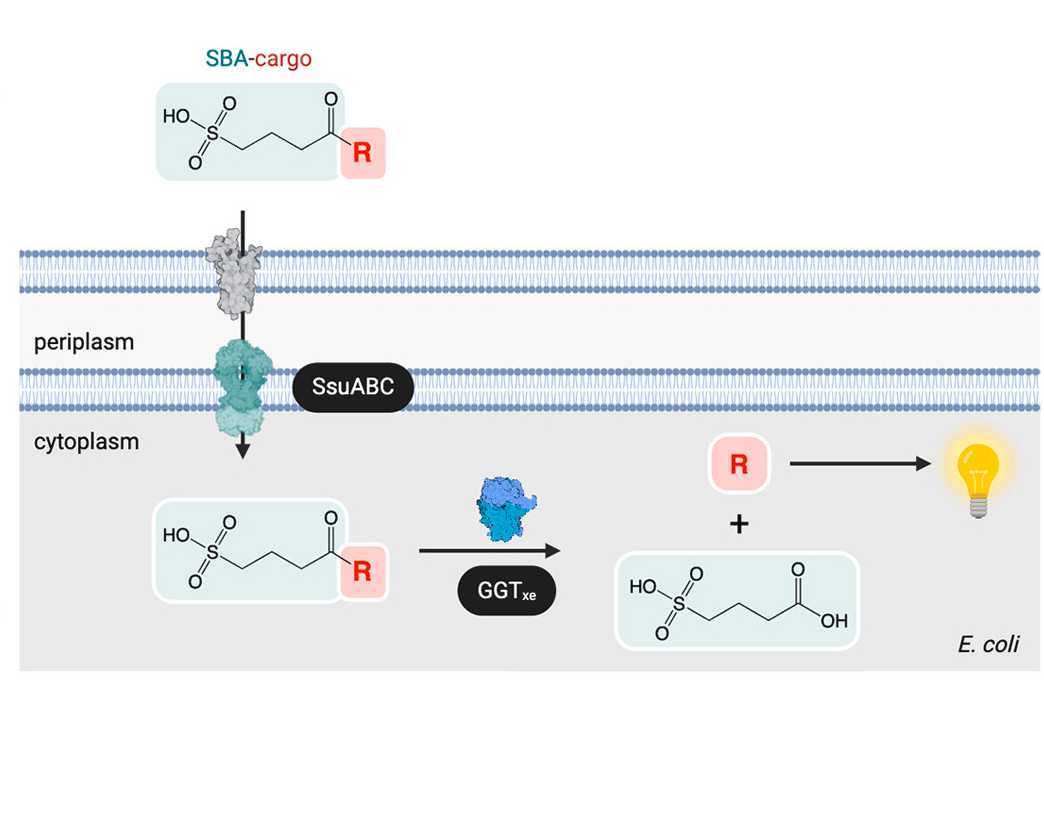
We designed a novel bacterial transport system to allow for import of novel coumpounds. The system takes advantage of promiscuous membrane transporters allowing passage of cargo molecules attached to a transport vector molecule.
external page DOI: 10.1111/1751-7915.70122
external page DOI: 10.1016/j.ymben.2024.05.005
These cargoes are then enzymatically unloaded from the vector releasing the cargo molecule inside the cell.
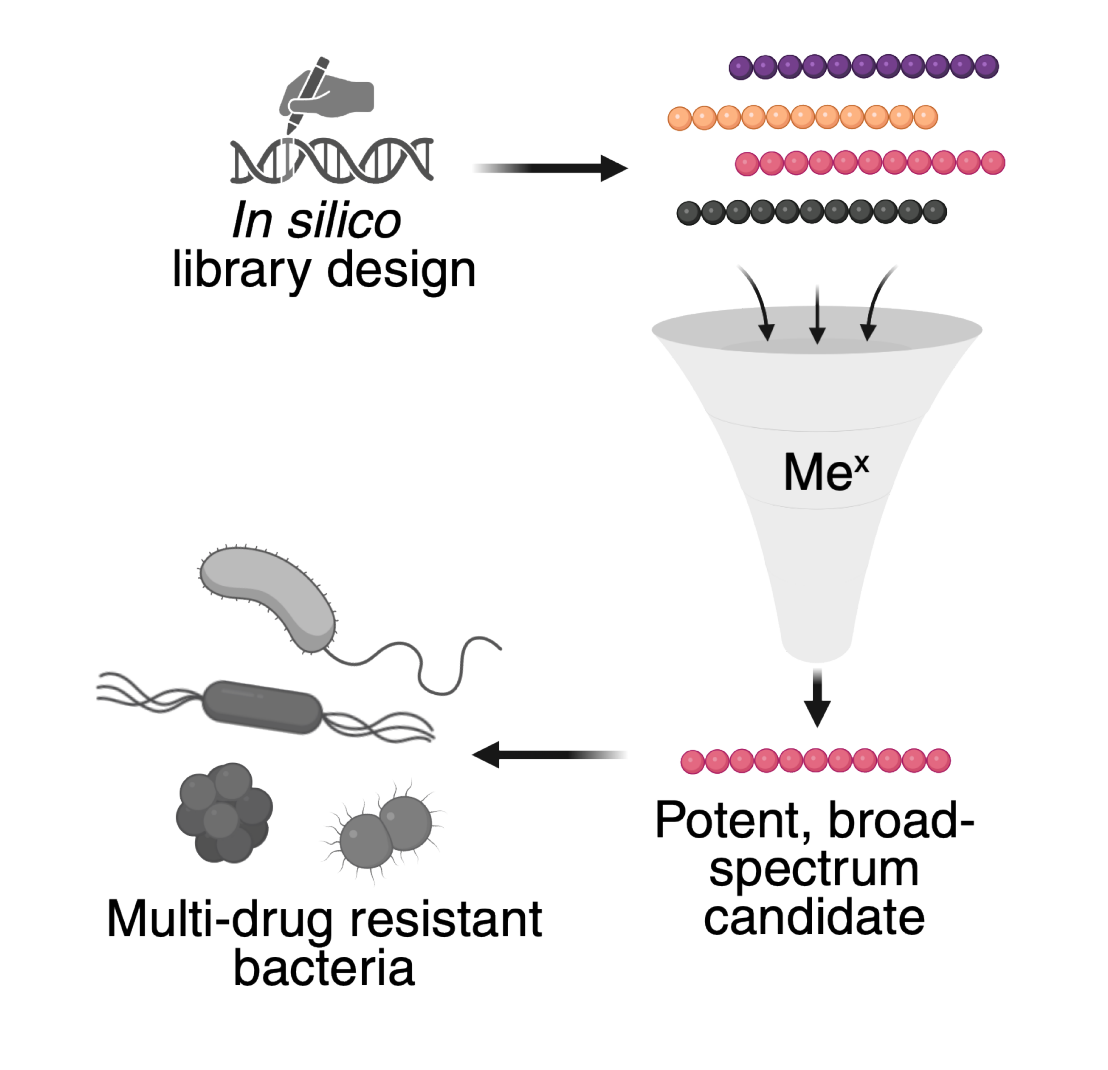
The global rise of multi-drug-resistant pathogens, particularly Gram-negative bacteria, highlights an urgent need for new antibiotic classes. Host defence peptides are promising candidates, known for their ability to disrupt bacterial membranes or penetrate bacteria and target crucial intracellular sites. By leveraging our Mex high-throughput platform, we can efficiently screen vast libraries of engineered host defence peptides and identify candidates with improved drug-like properties. This project aims to develop new therapeutic avenues to overcome existing resistance challenges, broaden the spectrum of treatable bacterial infections, and ultimately offer solutions against multi-drug-resistant threats.

We developed Mex, a powerful high-throughput platform for discovering and optimizing new antimicrobials. This technology uses Escherichia coli self-screening to rapidly assess the bioactivity of tens to hundreds of thousands of peptides. Thanks to E. coli's robust synthesis capabilities, Mex can screen vast libraries of both naturally occurring and synthetic peptide sequences, allowing us to quickly identify promising compounds.
Beyond discovery, we have applied Mex to establish the sequence-activity relationship for over 600,000 variants of Bac7, a potent natural antimicrobial peptide. This extensive data allowed us to rationally design and identify optimized candidates with improved activity against multidrug-resistant strains and favorable preclinical properties.
Mex represents a significant leap in discovering diverse, functional antimicrobials, accelerating the development of much-needed new treatments.


Many biologically active molecules, such as antimicrobial peptides (AMPs), ribozymes, and aptamers, require high local concentrations to exhibit measurable activity, making them difficult to discover de novo or optimize using conventional high-throughput screening methods. This project aims to establish a screening platform that addresses these limitations by producing DNA-encoded biomolecules in vitro and co-immobilizing them with their corresponding gene on individual high-capacity beads. This enables microfluidic-based functional screening while preserving genotype–phenotype linkage for identification via sequencing. The approach is intended to broaden the accessible sequence space for weakly active biomolecules, with a particular focus on antimicrobial peptides in the context of rising antimicrobial resistance.


Within the context of the NCCR AntiResist initiative, we use the hollow fiber reactor to simulate specific clinical infection scenarios. The studies performed in the hollow fiber system involve cultivation of bacterial isolates from patients in synthetic media, expose them to diverse antibiotic concentration profiles, and monitor antibiotic efficacy and antimicrobial resistance. This approach enables comprehensive analysis of the pharmacokinetics and pharmacodynamics (PK/PD) of both established and emerging antibiotic therapies.

We developed the nanoFleming platform for high-throughput screening of antibiotics secreted by wild-type microbial isolates or library-expressing hosts. Candidate strains and fluorescently labeled sensor strains—modeling microbial pathogens—are co-embedded in gel microcarriers. Secreted compounds diffuse within the carrier, allowing interaction while added low molecular weight nutrients support metabolic activity. If the candidate produces a bactericidal agent, sensor strain growth halts. Affected carriers are then sorted out via particle sorters based on their fluorescence intensity, operating at up to 100 Hz. From these, either the screening-positive strain or the DNA encoding the active compound’s biosynthetic pathway is recovered. Findings are verified in a secondary assay.

This work is funded by a Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung (SNSF) Ambizione grant [PZ00P3_202 090] to Nicolas Huguenin-Dezot.
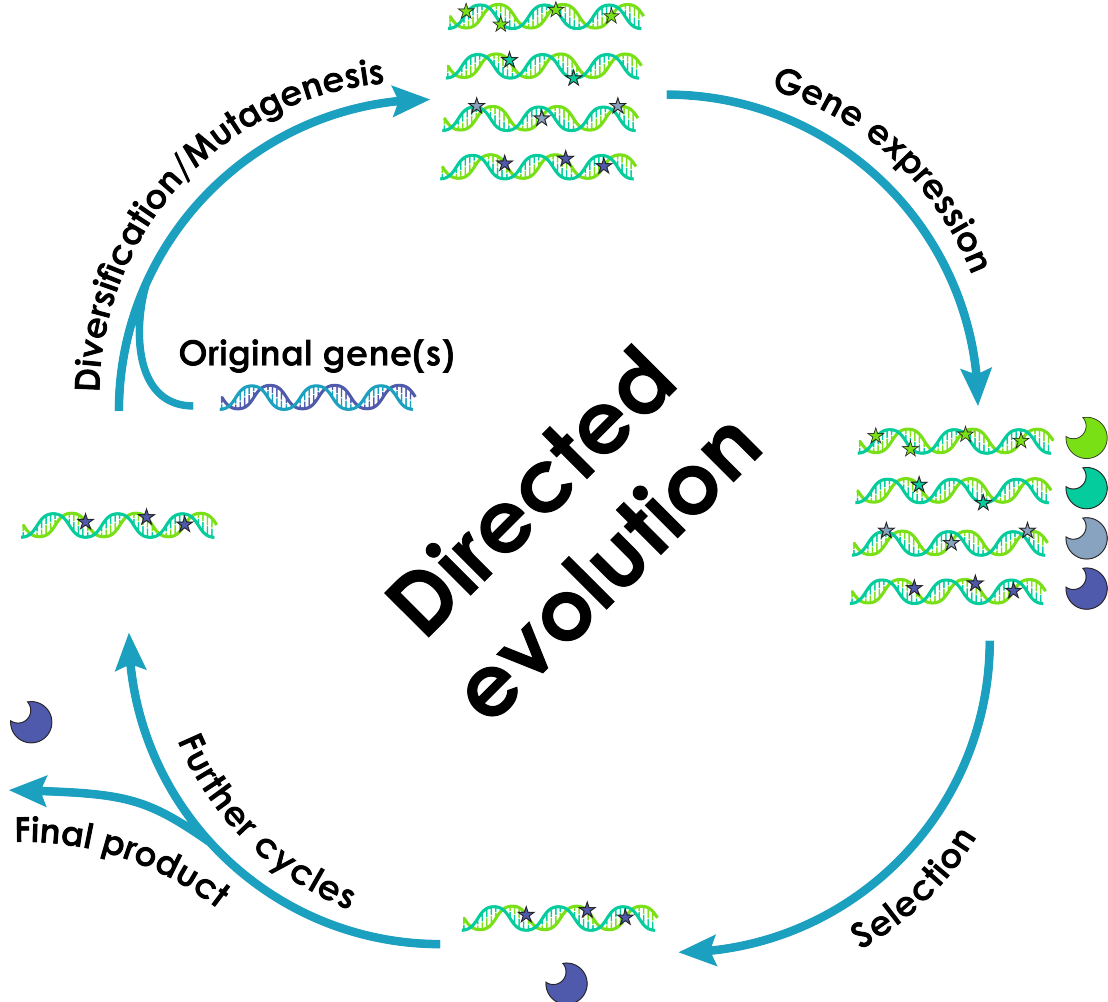
Proteins are involved in all processes of life and play crucial roles in endowing living matter with structure and function. The immense array of protein shapes and functions is the product of a long evolutionary process involving random mutation and selection, leading to successful versions of each protein tailored to the diverse needs of life. Directed evolution is a technique aiming to replicate and speed up this evolutionary process in the laboratory by introducing mutations into a gene of interest and selecting for variants with
enhanced or desired properties. Typically, mutations are introduced into the
gene of interest by one of several in vitro techniques. However, these
techniques are labour-intensive and relatively low throughput, and therefore
only allow to cover short evolutionary distances. An ideal laboratory evolution system would enable continuous in vivo mutagenesis of specific genes under simultaneous selection and over extended periods, without manual intervention. Such a system would allow the evaluation of large numbers of mutations and, hence, cover longer mutational paths. A first prerequisite for this is to confine in vivo mutagenesis to the gene(s) of interest to avoid the generation of unintended mutations that could negatively affect the genome of the host and interfere with the selection process.
Our group develops methods allowing such continuous directed evolution experiments. We developed an episome (plasmid) which replicates independently (orthogonally) from the genome of the host, using a dedicated set of replication enzymes, including an orthogonal DNA polymerase. Making this dedicated DNA polymerase error prone would restrict the accelerated introduction of mutations to this plasmid, without affecting the genetic material of the host. Such a system would generate vast pools of mutants in vivo, which could be simultaneously and continuously selected through carefully designed in vivo selection schemes and would enable directed evolution experiments to be run over long periods of time and therefore traverse long evolutionary paths.
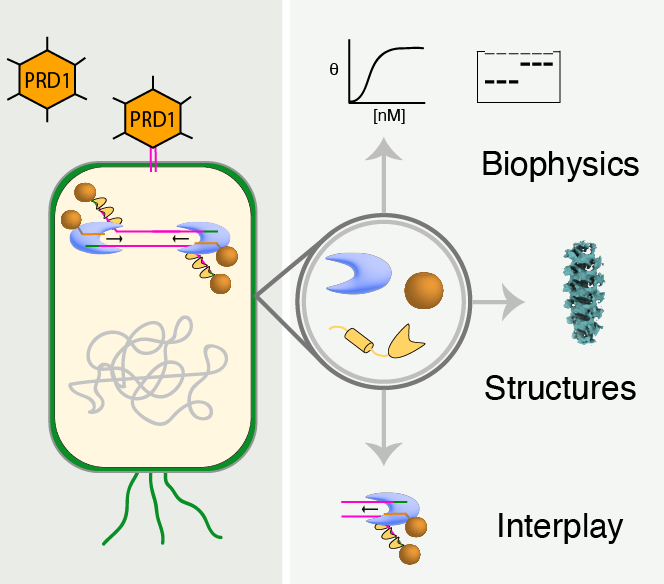
Protein-primed replication offers an elegant evolutionary solution to the challenge of replicating the ends of linear genomes. Unlike conventional DNA replication, which leaves unfillable gaps after RNA primer removal, this mechanism uses a specialised terminal proteins (TPs) as a primers, enabling complete genome replication. This project seeks to unravel the molecular mechanisms underlying protein-primed DNA replication in bacteriophage PRD1, a unique virus that infects Escherichia coli. This atypical process depends on a specialised set of viral proteins whose coordinated functions remain largely uncharacterised. Our main objective is to identify and systematically characterise all essential proteins involved in protein-primed DNA replication pathway of PRD1. We employ comprehensive biochemical and biophysical analyses to elucidate the individual roles and interactions of these proteins. In addition, we use advanced structural techniques, including cryo-electron microscopy and X-ray crystallography, to resolve the architecture of these protein complexes. We aim to provide fundamental insights into this biological process and broaden our understanding of this non-canonical DNA replication mechanism.
external page https://academic.oup.com/nar/article/53/5/gkaf132/8063246

Atom economy in catalysis ranks second only to waste reduction among the twelve principles of sustainable chemistry. A key challenge for achieving it is selectively functionalizing a specific carbon in molecules with multiple equivalent ones. While monooxygenases - once considered as “the beast” by Nobel Laureate Frances Arnold due to their engineering complexity - are often difficult to apply at scale, we developed two scalable processes using these enzymes for the synthesis of a textile chemical and an API intermediate. In both cases, we optimized key enzyme activities, engineered recombinant hosts, and scaled the processes to kilogram levels in collaboration with external partners. We also designed environmentally benign downstream protocols for product isolation and purification. The resulting biocatalytic routes demonstrated high robustness, excellent atom efficiency, and relied solely on aqueous systems, significantly reducing the use of fossil-derived inputs like organic solvents.
Learn more external page here.


Global efforts to achieve net-zero or even negative emissions are focusing on the development of non-fossil food products and materials. Gas mixtures comprised of CO2 and an energy-rich compound such as H2 are excellent feedstocks for reaching that goal.
These gases can be reacted by chemolithoautotrophic microbes to complex
structures such as protein for food applications or chemicals for polymerproduction.
However, many chemolithoautotrophs and their pathways remain poorly characterized and using them for industrial use is challenging. BPL is part of the EC-funded HYDROCOW consortium, with the Finnish company Solar Foods being in the lead and researchers from Imperial College London, the RWTH and the University of Groningen. BPL’s task is to develop and implement screening protocols for rapid activity benchmarking of large collections of variants of a protein-secreting, chemolithoautotrophic microbe. The optimized strains could be used by Solar Foods for manufacturing of proteins for net zero food markets.
external page DOI://doi.org/10.1039/D4SU00601A